はじめに
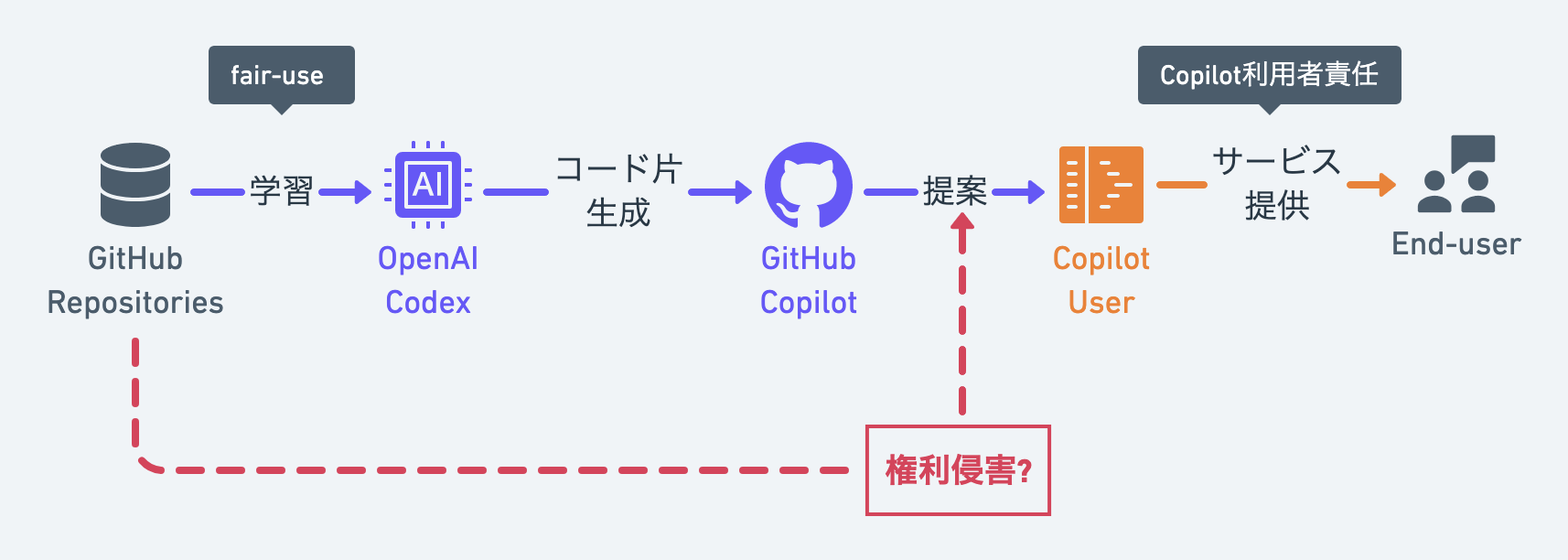
AIによるペアプログラミングを掲げるGitHub Copilotが正式リリースとなった1。
GitHub Copilotは、IDE上で自然言語でプログラムの情報を入力すると入力内容を満たすコード片を補完してくれるツールであるが、このコード片を生成するために用いられる機械学習モデルは、GitHub上で公開されているソースコードを元に学習されていると謳っている。
GitHub上に公開されているソースコードは、何かしらのオープンソースライセンスの元で公開されているものが大半であるが、そのようなソースコードやそのソースコードから生成された成果物を利用する場合、オープンソースライセンスの求める条項に従う必要がある。GitHub上のソースコードはインターネット上に公開された情報であるため、機械学習の学習対象として使用することは “fair-use” として認められていると解釈するのが一般的であるとは思うが、学習によって得られたモデルから生成された成果物(ここではCopilotが提案するコード片)の権利や権利侵害については確たる結論がないというのが現状であると思う。そのため、Copilotが提案するコード片は、GitHub上に公開されている他のプロジェクトの権利を侵害する、もしくはそのプロジェクトの設定したオープンソースライセンスの条項に反する利用となる可能性を含んでいる。この問題についてはTwitterやブログ2などでも言及されている。
弁護士プログラマによる GitHub Copilotの評価: Copilotが生成するコードが正しい保証はないし、つねにライセンス違反の危険があるため、多くの企業は使えないだろう。オープンソースはつねに明確なライセンスがあって機能してきた。だがCopilotにはそういうものが何もない。https://t.co/GHbcCBL1Nj
— 新山祐介 (Yusuke Shinyama) (@mootastic) June 29, 2022
本エントリでは、この問題に対してOpenAI社/GitHub社がどのような意見を持っているのかを調べ、また、プログラムの権利に関する判例やAI生成物に対する動向を元に、Copilotをどのように利用すべきかについての私見をまとめたものである。
筆者は法律の専門家ではなく、また、AIを取り巻く権利関係についての知識も乏しいため、本エントリで述べることは単なる個人の見解・私見であり、誤りが含まれる可能性があることに注意されたい。現時点での理解をまとめるため、自分に向けて書き残しているものである。
TL;DR;
長いので結論を先に。
- OpenAI社/GitHub社のCodex/Copilotに関する公開情報を見るに、両社とも学習元プロジェクトのコードと一致するコードが提案される可能性があることは認めているが、それが学習元プロジェクトの権利侵害に当たるとは考えていなさそう。
- プログラムの著作物性に関する国内の判例をいくつか見るに、Codex/Copilotが提案する規模のコード片に対して、学習元となったプロジェクトがその著作物性を主張することは難しのではないかという感想を持った。
- Codex/Copilotは学習元プロジェクトに対する権利侵害の恐れはないであろうという気持ちに傾いてはいるが、実際に企業で利用することを考えると、著作権の内国民優遇の特性やAI生成物の権利に関する議論を考慮した上で、利用には慎重になるべき だという考えを持った。
- AI生成物の権利に関する議論が進み、AIとのペアプロが発展していくことを願っています。
前提: オープンソースソフトウェアと権利
本エントリでは、主に、Copilot利用者とCopilotサービス提供者、OSSプロジェクトの三者に共通して関連する権利として特許権と著作権を取り上げる。
特許権では、「先願主義」「属地主義」が採用されており、特許庁への出願と審査請求を経て登録されることで権利が発生し、また、登録された特許であっても特許権の効力は出願先の国の領域内でのみ認められるものである。
特許権により保護される技術は、新規性・進捗性のある”技術”であるため、プログラム自体が特許として認められることはまずない(と思われる)。つまり、2つのプログラムの見た目が異なっていたとしても、そのプログラムによって実現されるアイディア・アルゴリズム等が特許として登録されている技術と同一であると認められる場合は特許権侵害となり得る事になる。
著作権は、ベルヌ条約/万国著作権条約により「無方式主義」「内国民待遇」が採用されているため、登録の必要なく認められる権利であり、かつ、条約加盟国間では外国で作成された著作物であっても内国著作物と同等の保護が保証されている。そのため、GitHub等でコードが公開されているプログラムは、どの国で作成されたものであっても等しく自動的に著作権で保護されることとなる。
また、著作権は、思想または感情を創作的に表現した著作物に対して与えられる権利であるため、特許権の場合とは違い、同一のアイディア・アルゴリズムを実現したプログラムであっても、その表現方法(プログラム)が異なれば個々のプログラムに著作権が発生し得る。
GitHub上のプログラムについて考えると、上述の通り、著作権は公開した時点(厳密には作成した時点ではあると思うが)で発生する権利であり、その瞬間から著作権によって保護される著作物となる。
しかし、公開されているプログラムを利用するために毎回著作権者の許諾を求めていてはソフトウェアの発展が妨げられてしまうため、オープンソースとして公開されているプロジェクトの多くは、著作物であるプログラムの自由な利用・改変・頒布等を一定の条件の元で認めることを表明するためにOSSライセンスを設置している。
ただし、OSSライセンスの中でも制限が緩いと言われているMITライセンスであっても、利用する側のプロジェクトに対して元のプロジェクトの著作権表示と許諾表示の記載を求めており、OSSのプログラムを利用する場合はほぼ必ず何かしらの対応を取る必要がある。 (数多く存在するライセンスの中には、何も対応を求めないライセンスもある3。また、それらのライセンスはOSDによる定義4に適合していないため、OSSとは言わないという話もある。細かい話をするとキリがないのでMIT, Apache-2.0, GPL等のメジャーなライセンスのみを頭に浮かべながら書いている。メジャーなライセンスとは何かという話も(ry。 )
問題点: GitHub Copilotの学習元プロジェクトに対する権利侵害
2022/06にGitHub Copilotが正式サービスとしてリリースされた。
「はじめに」でも述べたが、Copilot正式リリースが話題に上るとともに、Copilotが既存プロジェクトのコード片と合致するコードを提案する可能性があることへの懸念に関する言及も多くあった。
後述するが、まず、GitHub等のインターネット上に公開されているデータを機械学習の用に利用することは"fair-use"である。また、サービス提供者であるGitHub/OpenAI社は、GitHub Copilotが提案するコード片をどのように扱うかについてはCopilot利用者側に責任があるとしており、Copilotを利用して開発されたソフトウェアに権利侵害が見つかった場合、それは利用者側の責任ということになる。これらの点については、調査の対象外とする。
本エントリでは、「GitHub CopilotがCopilot利用者に対して提案するコードが学習元プロジェクトの権利侵害にあたらないか」という点について主に取り上げている。
調査: 開発側(GitHub社, OpenAI社) の解釈についての推察
GitHub Copilotおよび、その裏で動いているOpenAI Codexを開発/提供しているGitHub社,OpenAI社がこの問題についてどのように捉えているのか、公開情報を元に調べてみた。
OpenAI社
GitHub Copilotの裏で使われているOpenAI Codexについては2021/07に論文が公開されている。
[2107.03374] Evaluating Large Language Models Trained on Code
(その他、OpenAI社のブログにCodexに関する記事56が2本ほどあるが、求めているような情報はなかったため省略する)
論文の内容は大体以下の通り。
ソースコードに特化していない普通のGPT-3でも簡単なプログラミングタスクを解くことができたことから「よりソースコードに特化した学習を行うことで多様なプログラミングタスクを解くことができるのではないか」という仮説の元、GitHubで公開されているソースコード等にfine-tuneされたGPT language modelとしてCodexを開発。本論文では、Pythonを対象言語とし、自然言語で書かれたdocstringから標準的なPython関数を生成できるかについて評価を行っている。生成されたプログラムの評価フレームワークとして HumanEval を提案し、データセットをGitHub上で公開している。
本論文において、OSSライセンスや権利関係についての記述がないかみてみると、学習に使用したGitHub上のリソースについては 3.1. Data Collection に言及がある。
3.1. Data Collection
Our training dataset was collected in May 2020 from 54 million public software repositories hosted on GitHub, containing 179 GB of unique Python files under 1 MB.
この後にもファイルサイズやプログラムの性質によるフィルタリングについての言及があるが、学習元のプロジェクトのライセンス等への言及は特にない。
また、7.7. Legal implications にて、法的な問題について言及がある。ここが本題。
まず、”インターネット上で公開されているデータセットをAIの学習に用いることは “fair-use” であると認定されている” 7 ことについて触れている。
To begin with, the training of AI systems on Internet data, such as public GitHub repositories, has previously been identified as an instance of “fair use” (O’Keefe et al., 2019).
これを元にすると、GitHubに公開されているコードを、そのコードがどんなライセンスの元で公開されていたとしても、学習に利用すること自体は “fair-use” であると考えられる。(「このプロジェクトのコードは機械学習に利用してはいけない」という条項を含むライセンスの元でコードを公開するというトロール仕草もあるだろうが、ここでは考えない。)
余談だが、日本国内においても、平成30年5月に成立した「著作権法を一部改正する法律8」において著作物の利用に関する規定が変更され、情報解析の用に用いる場合は著作物であっても無許諾で利用できるようになっている。
次に、Codexモデルが、稀に学習元と同じコードを提示してしまう事象について触れている。
Our preliminary research also finds that Codex models rarely generate code that is identical to the contents of training data.
これの原因として、学習元からそのままコピペしている訳ではなく、提示されたコードが学習時に何度も出現するようなプログラミング言語における一般的な表現や規約であるため、モデル内の予測的な重みづけによって学習データと同じようなコードが生成されることがあるということを挙げている。(後述のGitHub CopilotのFAQ 9 では、もう少し深くこの問題について触れている)
これは個人の感想だが、GPLでライセンスされたプロジェクト内のコードと同一の部分があったとしても、その部分がプログラミング言語における規約や標準的な記法の範疇と判断されるならば、開発者の創作性は認められず、GPLの求める一定の条件に従う必要はないのではないかと思う。元のプロジェクトと同一のソースコードが生成されたこと、それ自体が問題なのではなく、どのようなコードが生成されたのかによって扱いが変わる類の問題のように思う。
また論文では、生成されるコードはユーザーの入力によって変化するものであり、かつ、提示されたコードを編集したり受け入れたりするなどの最終的な判断はユーザー自身に委ねられている点についても触れている。
Generated code is also responsive and customized to the user’s input, and the user retains complete control over editing and acceptance of the generated code.
穿った見方をすると、”OpenAI社は(場合によっては)著作権違反となるコードを提案しているのにも関わらず、利用者側にその責任をなすりつけようとしている”ようにも読めてしまうが、同じOpenAI社のDALL-E 2の生成物が商用利用可能となった10ことを考えると、OpenAI社としてはCodexにより提案されるコードもその著作権は利用者が有するものであると判断しているように個人的には思える。
この章の最後では「我々の責任ある安全なAIに対するコミットメントには、コード生成システムの広範な知的財産権に対する継続的な注意が含まれる」と述べられており、また、政策立案者(policymaker)との対話についても触れられている。
Our commitment to responsible and safe AI includes continued attention to the broader intellectual property implications of code generation systems. We intend to remain engaged with policymakers and experts on these issues so that the users of such systems can ultimately deploy them with confidence.
OpenAI社としても、現時点ではCodexの利用が権利侵害等に侵害等に繋がる事はないと判断しサービスのリリースは行なっているものの、未だ曖昧な部分はあると認識しており、今後、法整備等に向けた活動を行なっていくというところでは無いだろうか。(OpenAI社に肩入れした意見に見えることは認識している)
GitHub Copilot
次にGitHub側の公開情報に権利関係の記述がないか調べた。
Copilot内部で利用しているOpenAI Codexが提案するコードに仮に権利侵害の危険性があったとしても、実際に利用者に提案される前に内部的に棄却される仕組みを備えているのであれば、問題を回避できるていると考えられる可能性もある。
Copilotに関する公開情報の中では、GitHub CopilotのFAQに関係しそうな記述があったため、いくかFAQを取り上げる。
GitHub Copilot · Your AI pair programmer
Does GitHub Copilot recite code from the training set?
The vast majority of the code that GitHub Copilot suggests has never been seen before. Our latest internal research shows that about 1% of the time, a suggestion may contain some code snippets longer than ~150 characters that matches the training set. Previous research showed that many of these cases happen when GitHub Copilot is unable to glean sufficient context from the code you are writing, or when there is a common, perhaps even universal, solution to the problem.
このFAQでは、OpenAI社の論文と同様、,u>Copilotが提案するコードの中に学習元と同一のコードが含まれる可能性があるという問題について述べているが、こちらはOpenAI社の論文よりも踏み込んだ調査をしている。11 このFAQでは、約1%の確率でCopilotの提案するコードの中に学習元のコードと一致する150文字以上のコード片が含まれる可能性があると述べている。また、この事象は、利用者の記述からうまくコンテキストを抽出することができず、よく現れる一般的なパターンを提案してしまったためと説明されているが、同一のコードが提案されることによるOSSライセンス上の問題等については特に触れていない。
これは個人の考えだが、150文字以上の一致となるとプログラム自身に創作性が認められる可能性が十分にあるようにも思えてしまうが、I/O関係の処理などはエラー処理も含めると長いお作法となりがちなので、文字数だけでは語れず、やはり実際にどのようなコードが一致したのかを見ないとなんとも言えないと感じてしまう。
Does GitHub own the code generated by GitHub Copilot?
GitHub Copilot is a tool, like a compiler or a pen. GitHub does not own the suggestions GitHub Copilot generates. The code you write with GitHub Copilot’s help belongs to you, and you are responsible for it. We recommend that you carefully test, review, and vet the code before pushing it to production, as you would with any code you write that incorporates material you did not independently originate.
こちらのFAQでは、Copilotが提案したコードを利用した書き上げたコードは利用者自身に帰属し、その責任も利用者が負わなければならないと言っており、Copilot利用者の成果物に対する権利侵害の注意喚起を行なっているが、Copilotが提案するコード自身の権利侵害については特に記述されていない。Copilotの利用規約にも同様のことが書かれている。
GitHub Terms for Additional Products and Features - GitHub Docs
The code, functions, and other output returned to you by GitHub Copilot are called “Suggestions.” GitHub does not claim any rights in Suggestions, and you retain ownership of and responsibility for Your Code, including Suggestions you include in Your Code.
OpenAI社の論文でもそうであったが、GitHub側のステートメントでもCodex/Copilotが提案するコード片自体に権利侵害の恐れはないと暗に判断しているということが伺える(そうでもなければサービス化なんてできないだろうが)。また、このFAQでは、GitHub Copilotが道具である (GitHub Copilot is a tool)と明に言っており、AIを道具として使用した際の生成物の著作権に関する議論を意識しているようにも読める(この辺りの議論ついては後述の余談のところで少し触れている)。
What can I do to reduce GitHub Copilot’s suggestion of code that matches public code?
We built a filter to help detect and suppress the rare instances where a GitHub Copilot suggestion contains code that matches public code on GitHub. You have the choice to turn that filter on or off during setup. With the filter on, GitHub Copilot checks code suggestions with its surrounding code for matches or near matches (ignoring whitespace) against public code on GitHub of about 150 characters. If there is a match, the suggestion will not be shown to you. We plan on continuing to evolve this approach and welcome feedback and comment.
このFAQでは、GitHub Copilotに提案内容が公開コードと一致しているかチェックする機能が存在し、一致している場合は提案しないようもできるオプションを備えていると言っている。
このオプションはGitHubのSetings > GitHub Copilotから設定することができるようだ。
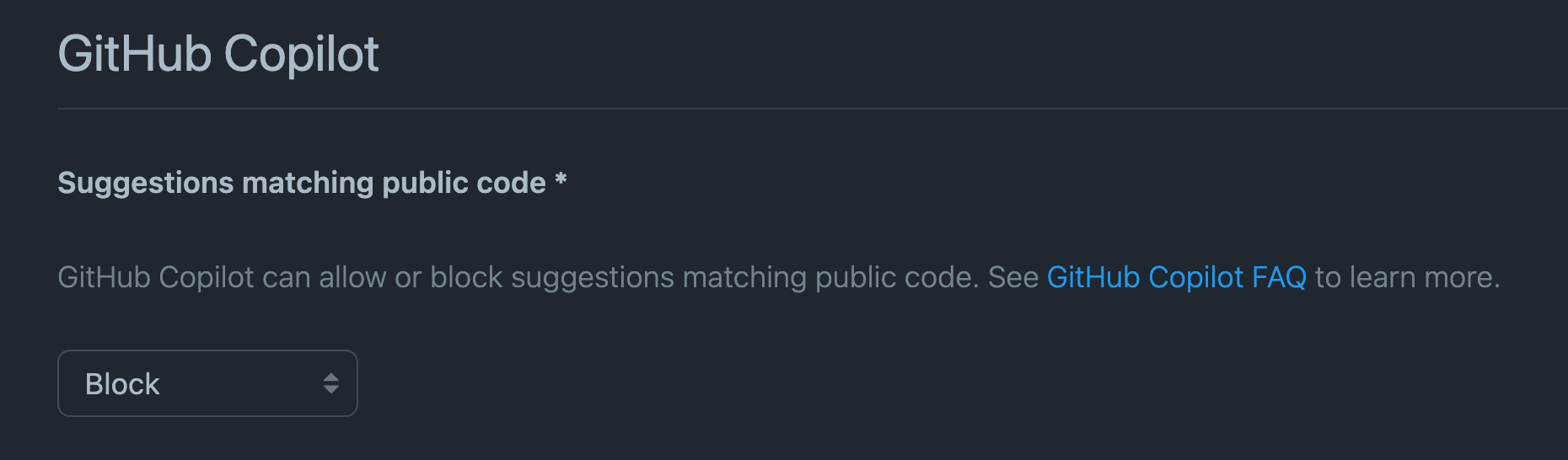
ひとつ前のFAQより、GitHub社自身はCopilotの提案するコードが直接的に他者の権利侵害に繋がることはないと判断しているように思えるが、AI生成物の権利について未だ確たる結論がない以上、公開コードとの一致による権利侵害に懸念を持っている利用者もいるはずであり、そのような人向けのオプションも用意しているということだろうか。
少し脇道に逸れるが、ここで生じる新たな疑問として「コードの完全な一致(maching)さえ防ぐことができれば、学習元プロジェクトに対する権利侵害を回避できるのか?」というものがある。
特許権に照らして考えると、特許は実装それ自身ではなくアイディアに対して認められるものであるため、もちろんNoである。しかし、Codex自体がコーディングタスクを解くためのモデルであることを考えると、特許権を侵害するほどの実装を提案するということがあるかという疑問が残る。また、前述の”約1%の確率で学習元コードと一致”という事象はあるが、この時提案されているのは言語共通の実装であるため、それが特許権を侵害したコードであるとするのであれば、すでに特許権を侵害したコードが複数公開されていることになり、Codex/Copilotの問題ではないように思う(Codex/Copilotの責任が消える訳ではないが)。もちろん、Codexの性質や、学習元と一致している提案コードの内容はサービス提供側のOpenAI/GitHub両社の言い分に元付いているため、これらに対する疑義は残るものの、Copilotの提案レベルのコードで特許権の侵害が発生するとは考えにくいというのが個人の感想。
次に、著作権に照らして考えてみる。著作権は表現方法に対して与えられる権利であるため、もちろん完全に一致している場合は権利侵害にあたる。しかし、完全な一致を弾いたとしても、コードに関してはどこまで似ていれば表現が同じだと解釈されるのかは個人的に気にはなる(例: 空白文字が違う、変数名が違う、処理の順序が違う、等)。この点を掘り下げるために、プログラムとソフトウェアに関する判例について少し見てみた。
東京地裁 平成28年(ワ)第36924号 1213
本判決において、原告側は、開発したプログラムの機能及び特徴からプログラムの著作物性を主張している。しかし、裁判所側の判断は以下である。
著作権法は,プログラムの機能やアイデアを保護するものではなく,その具体的表現を保護するものであるところ,プログラムにおいては,所定のプログラム言語,規約及び解法に制約されつつ,コンピューターに対する指令をどのように表現するか,その指令の表現をどのように組み合わせ,どのような表現順序とするかなどについて作成者の個性が表れることになる。
したがって,プログラムに著作物性があるというためには,指令の表現自体,その指令の表現の組合せ,その表現順序からなるプログラムの全体に選択の幅があり,かつ,それがありふれた表現ではなく,作成者の個性,すなわち,表現上の創作性が表れていることが認められる必要がある。
ここで述べられているプログラムの著作物性の特徴に関して「プログラムに著作物性があるというためには…プログラム全体の選択の幅があり…」という部分が気になった。当然ではあるが実装するプログラムの責務を増やすほど、また、コードの量が増えるほど、プログラム全体の選択の幅は広がる。実際、プログラムの著作物性が認められた判例1415では、著作物性が認められる要因としてソースコードが大量であったことが大きく寄与しているように見える。もちろん、量が多いこと自体が独創性に寄与する訳ではないが、プログラム選択の幅が増えることで独創性を主張できる余地が広がり、逆にいうと量が少ないと独創性を主張する余地が少なくなる。Codexの解こうとしているコーディングタスクレベルの要求で、著作物性が認められるほどの選択の幅が存在するかというと、個人的には疑問がある。
また、この判例において、原告側はプログラムの表現上の特徴を以って独創性を主張しているが、これは裁判所により棄却されている。
また,原告は,本件プログラムには,①クラス,関数,変数などは全て小文字を使用すること,②クラスメンバ変数名の先頭には「_(アンダースコア)」を付することなど,表現上の特徴があると主張するが,これらの表記方法は,関数その他の指令単体の表現の特徴であって,その組合せに係る表現の特徴ではない上,いずれもありふれた表現ということができるから,本件プログラムに著作物性があるということはできない。
著作権自体は表現に対して与えられるものであるが、それがありふれた表現であると著作物性が認められない。一般に、プログラムを記述する際は誰が読んでも自然に読めるよう「可読性」を念頭に置くことが多く、できるだけありふれた表現を使用することが求められることが多い。また、プログラミング言語を決定した時点で使用できる言語仕様・APIなどは限定されるため、選択の幅は限られる。これにさらに、Codex/Copilotの解こうとしている問題が標準的なコーディングタスクであることを考慮すると、著作物性が認められるほど独創的なコードが提案されるとはやはり考えにくいというのが個人の感想である。
以上より、個人的な感想ではあるが、Codex/Copilotにより提案されるコードが学習元のコードの著作権を侵害する事象が起こるとは考えにくい。もちろん、この判断は現時点でのCodex/Copilotの公開情報からその能力を想像した上での判断に過ぎないため、実際に使ってみると著作権侵害となるコードが多数提案されるのかも知れないし、今後の改良等でこれらの前提が変わる可能性もある。さらに、最終的に著作物性の判断は人が行うこととなるため、AIの側で著作権侵害に当たるコードの提案のみを取りやめるということは恐らく不可能であるため、Copilotによる学習元プロジェクトに対する著作権侵害のリスクが完全になくなるということは無いと思われる。
余談: AI生成物の権利に関する議論に寄せて
最後に、AIが生成する成果物の権利について調べたことを書き残す。
AIを利用する際に、そのAI利用者からのAIへの指示に利用者の創作意図や創作的寄与が認められ、AIをその利用者の指示を具現化するための単なる道具として使用した場合、AIからの生成物の著作権は利用者に帰属するという考え方がある1617。
Copilotをソフトウェア開発に用いることを想定すると、まずCopilot利用者は開発するソフトウェアの要件・仕様を頭に描いているはずであり、その中の一部分の実装について、その部分が満たすべき仕様をdocstringとしてCopilotに与え、Copilotがその実装を返す、という利用シーンが一般的であると考えられる(遊びの用途であればこの範疇でない)。この**「開発するソフトウェアの要件・仕様を頭に描く」や「Copilotに仕様を与える」という行為から、個人的にCopilot利用者の創作意図や創作的寄与は十分に認められるのではないか**と考えられる。そのため、前述のAI生成物に関する著作権の話に照らし合わせれば、Copilotを利用することはAIを道具として利用したに過ぎず、Copilotにより提案されるコードの著作権はCopilot利用者に帰属すると考えることもできる。そして、もしCopilotが提案するコードが特許権を侵害しているのであれば、特許はアイディアに対して認められる権利であるため、利用者がCopilotに与える仕様自体が権利侵害に当たるはずである。そのため、特許権侵害はCopilot利用者側で防ぐものであり、実装にCopilotを用いたかどうかによって結論が変わるものではないと思われる。
これより、「AI利用者に十分な創作意図・創作的寄与が認められ、AIを道具として使用しているだけであれば、その生成物の著作権はAI利用者に帰属する」というような考えが認められれば、Copilotの利用が特許権・著作権侵害に当たるとは考えにくい。
と、ここまで書いて一旦は納得していたが、改めて全体を読み直すうちに、この解釈はプログラムの著作物性の要件と合致しない可能性があることに気がついた。今一度、判例「東京地裁 平成28年(ワ)第36924号13」にあるプログラムの著作物性の要件を再度載せる。
したがって,プログラムに著作物性があるというためには,指令の表現自体,その指令の表現の組合せ,その表現順序からなるプログラムの全体に選択の幅があり,かつ,それがありふれた表現ではなく,作成者の個性,すなわち,表現上の創作性が表れていることが認められる必要がある。
ここでは、プログラムの著作物性があると言うためには「指令の表現自体、その指令の組み合せ、その表現順序」に表現上の創作性が表れていることが必要だと言っている。AIを道具として利用してプログラムを生成する場合に、プログラムの著作物性という観点でAIへの指示内容に創作意図や創作的寄与が認められるためには、AIに対する指示に「指令の表現自体、その指令の組み合せ、その表現順序」に関する記述が含まれる必要があるのではないか。つまり、AIの生成するコードに対する創作的寄与としては「AとBのAPIを、この通りの順序で呼んでZからファイルを読み込む処理」のようなプログラムの表現に対する具体的な指示を含める必要があるのではないかと思った。Codex/Copilotの用途として想定されている「AとBからCを計算する処理」と言う抽象的な指示であれば、ソフトウェア全体または部分としての創作意図や創作的寄与は十分に認められるとは思うが、著作物性のあるプログラムを生成するための指示としては、創作的寄与が不十分であるとも考えられる。
ただし、このことはAIの生成するコードが自分の著作物であると主張するには不十分であるということであり、AIの生成するコードが著作権を侵害しているかどうかという問題には関係しないようにも思う。先にも述べたが、生成されるコードは表現上の創作性が現れるほど大規模なコードにはならないと考えられるため、多くの場合では問題とはならないと個人的には捉えている。(ただし、AIの生成するコードが自分の著作物だと主張できない場合、そのようなコードをどのように扱うべきかと言う問題は残る。OpenAI/GitHub社の公開文書からは、提案コード自体は利用者の著作物にはならないため、finish workを行うことで自分に著作とせよという意図を汲み取ることもできる。)
以上の話は、AI生成物の権利に関するある一つの解釈に基づく話であって、実際のこのような法律や法解釈がある訳ではない(と思われる)。公開情報の機械学習への利用がfair-useと認められたことと同様、AI生成物に関する権利侵害の話について、法整備も含めた今後の動向を注視する必要がある。
感想
まず、本調査を行う以前より、AIとのペアプロという体験については賛成の立場であった。というのも、自分が開発をする際も、自分でコードを書くときと、人のコードをレビューするときでは視点が変わると感じていたからである。自分でコードを書いてしまうと、どうしてもバイアスがかかってしまうために自分でレビューすることは難しい(見直し程度であればできるが)。つまり、レビュワーが一人減ってしまうことになる。伽藍とバザール18にあるように、目玉の数が多いほどバグは見つかりやすいため、元となる実装はAIにやってもらい、自分はそれを見る目玉の一つ(2つ)となることができれば、多少なりともバグを減らす影響があるのではないかと考えているからである。
8. ベータテスタと共同開発者の基盤さえ十分大きければ、ほとんどすべての問題はすぐに見つけだされて、その直し方もだれかにはすぐわかるはず。
あるいはもっとくだけた表現だと、「目玉の数さえ十分あれば、どんなバグも深刻ではない」。これをぼくはリーヌスの法則と呼んでる。
もちろん一人増えただけでは「目玉の数さえ十分」とは言えないが、OpenSSL/Heartbleedの問題で明らかになったように、重要なインフラを担うプロジェクトでさえ開発者の数が少ないとなると、一つであっても目玉を増やす活動というのは意義があるのではないかと期待している。
Copilot周りの権利関係について調べてみた結果としては、OpenAI社もGitHub社もCodex/Copilotが生成するコードの知的財産権への影響に関する意識は持っており、両社とも現時点ではCodex/Copilotは問題にはならないと判断し、また、Codex/CopilotによってAI生成物の権利に関する議論を促進するという姿勢であるのだと個人的には感じた。また、過去の判例からプログラムの著作物性の要件を知り、Codex/Copilotの提案するコードレベルでは、学習元プロジェクトが提案されるコードに対して著作物性を主張するのは困難なように思えた。ただし、調べた判例は国内だけのものであり、著作権は内国民優遇の特性を持つため、海外の判例まで含めて調べきれないとなると、安易に「Codex/Copilotが権利侵害となることはほぼない」と言い切ることができない。また、AI生成物の権利や権利侵害については各国で議論が進んでいるところであると思うので、GitHub Copilotのような影響力の大きいツールが正式リリースされたことにより、この辺りの議論がさらに深まることに期待したい。(現時点の議論も全然追えてはいないが…)
最後に、自分がCopilotの利用者であると考えると、個人としての立場としては利用しても良いと思えるが、企業として利用することは難しいのかと思った。他者の権利侵害リスクにのみ着目すると、自己レビューの段階で著作物性が認められそうなコードを弾くことで対応はできるように思う。ただし、その場合Copilotが著作物性のあるコードを提案すること自体は認めることとなり、職業倫理に照らし合わせると、使用すること自体がCodex/Copilotの権利侵害を認めることとなり、使用が難しいのではないかと思った(この線引きも微妙である感は拭えないが)。
いずれにせよ、自分はCopilot無償利用枠からは漏れており、課金して使うほどとは思っていないので、当面の間は利用することはないとは思うが。
余談: Amazon CodeWhisperer
GitHub Copilotの正式リリースと同時期にAmazon社もCodeWhispererという、Copilotに似たサービスを発表19したので、そちらについても少し見てみる。
Amazon CodeWhispererは、GitHub Copilotと同様、開発者によるコメント (docstring) を元に、実装を提案するツールのようだが、提案されるコードの内容に最適なクラウドサービスやパブリックライブラリの選択が含まれるらしいので、GitHub Copilotより広範なタスクを扱えると言っているように見える。
CodeWhisperer はコメントを自動的に分析し、指定されたタスクに最適なクラウドサービスとパブリックライブラリを決定し、ソースコードエディタで直接コードスニペットを推奨します。
また、学習元プロジェクトに対する権利関係で大きな違いとして、Amazon CodeWhispererは、提案されたコードがトレーニングデータと類似している場合、それを検出して表示する機能が付いているらしい。
このサービスには、推奨コードが特定のトレーニングデータに類似しているかどうかを検出するリファレンストラッカーも含まれています。開発者はコードの例を簡単に見つけて確認し、プロジェクトでそのコードを使用するかどうかを決定できます。
CodeWhiperer の解説記事20の方に、スクリーンショット付きでこの機能の解説がある。
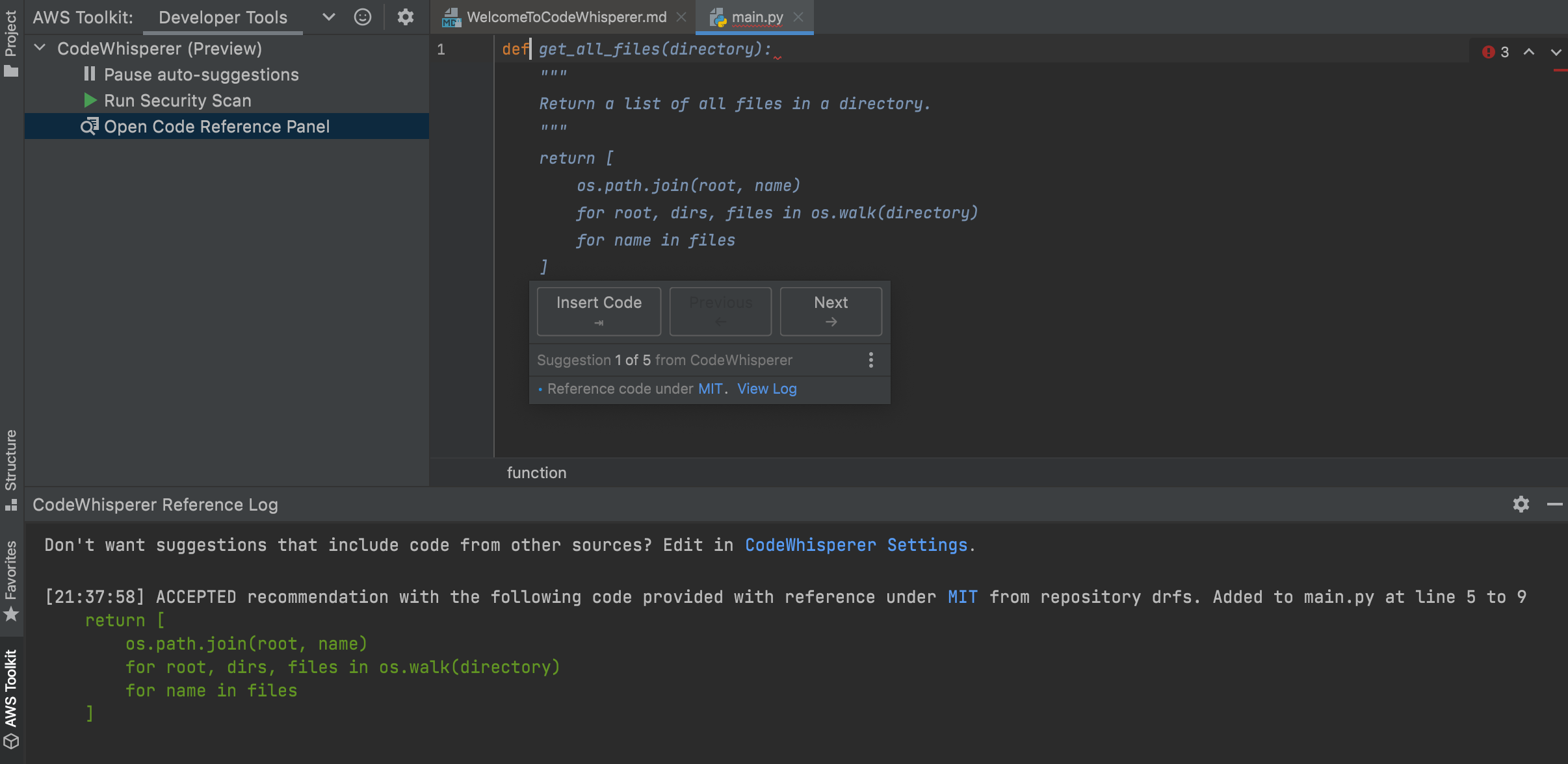
これを見ると、確かに採用した提案コードがどのようなライセンスの元で公開されているのかを一目で確認でき、採用不採用を決定するのに役に立ちそう。
少し気になったので、スクリーンショットで例として表示されているリポジトリの記述が正しいのか調べてみた。
github drfs で検索すると https://github.com/datarevenue-berlin/drfs がヒットし、このリポジトリはMITライセンスで公開されており、また、S3に関する処理があり、Pythonで書かれていることから、このリポジトリの例を表示しているように見える。このプロジェクトの2021/12/23最新コミットで、提案されているコードと同様の記述を探すと、以下が見つかる。
@return_pathlib
@allow_pathlib
def walk(self, path):
"""Walk over all files in this directory (recursively)."""
return [
os.path.join(root, f) for root, dirs, files in os.walk(path) for f in files
]
このメソッドは、改行位置や変数名が異なるものの、提案されているコードと等価な記述であるため、動作としては特に問題がないように見える。
ただ、提案されているコードと学習元のコードの間に変数名の違いがある点について、トレーニングセットとして datarevenue-berlin/drfs のコードを使用しているとした場合、学習元のコードから提案内容のような変数名の変換を機械的に行うことは難しいように見える。学習元の記述 os.path.join(root, f) から提案内容の os.path.join(root, name) へ変換する場合、 join の第2引数がファイル名を表す文字列であると知っていなければ変数名の変換を行うことは難しく、人の手を加えないとスクリーンショットにある提案内容にはならない気がしている。もしくは、このリポジトリ以外にも提案内容のリファレンスとなるリポジトリがあるか。ただ、いずれにせよCodeWhispererの動作に怪しい点があると言えるだけの材料にはならないので、単純に”気になった”というレベルの話。
もう一点気になったのが、このように学習元のライセンスを表示する場合、CodeWhisperer自身がOSSライセンスの求める条項に従う必要があるのではないかということ。このスクリーンショットではMITライセンスのプロジェクトのコードを提案内容のリファレンスとして利用したと表示されているが、その場合、CodeWhispererはMITライセンスの求めに従い、このプロジェクト (drfs) のライセンス文と許諾表示を記載する必要があるように思う。もちろん、それだけであればそのようなページなりを作成すればいいのだが、例えばここでGPLでライセンスされたプロジェクトがリファレンスとして表示されると、話は厄介になるように思う。CodeWhispererのFAQ21を見ても、「オープンソースのコードを学習に使用した」程度にしか書かれていないため、ライセンスによって学習対象としてのフィルタリングを行なったかどうかについては書かれていない。
Q. Where did AWS obtain the training data to build this service?
CodeWhisperer code generation is powered by ML models trained on various data sources, including Amazon and open-source code.
このあたりの動作は気になる点ではあるが、これらは「もし、リファレンスログに表示されるプロジェクトのライセンス表示がなければ」や「もし、GPLのコードがリファレンスとして表示されれば」などの仮定に基づいた懸念点であり、実際に触ってみれば解消する類の問題なのかも知れない。
最後に、FAQ21の中の気になる記述について。
Q. Who owns the code generated by CodeWhisperer?
Developers own the code and are responsible for it.
ここでは、簡潔にCodeWhispererの生成するコードは開発者のものであると言い切っているが、AI生成物の権利に関する議論に照らすと、何に基づいて権利が開発者に帰属すると言っているのか分からないのが少し気になった。(自分が知らないだけで、そのような決定があったのかも知れないが。)この点については、OpenAI/GitHub社のような、「Codex/Copilotにより提案されたコードに対して弊社は権利を主張しないが、提案されたコードを利用して書いた成果物に対する責任は開発者自身が負う」という書き方の方が誠実なように見えた。
The Open Source Definition (Annotated) | Open Source Initiative ↩︎
https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/ ↩︎
≪プログラムの著作物につき,著作物性(創作性)が否定された事例≫ | 知財弁護士.COM|知的財産紛争・企業法務のご相談なら弁護士法人内田・鮫島法律事務所 ↩︎ ↩︎
ntroducing Amazon CodeWhisperer, the ML-powered coding companion | AWS Machine Learning Blog ↩︎
ML-Powered Coding Companion for Developers – Amazon CodeWhisperer FAQs – Amazon Web Services ↩︎ ↩︎